


Monster Scale Summit
Curious how leading engineers tackle extreme scale challenges with data-intensive applications? Join Monster Scale Summit (free + virtual). It’s hosted by ScyllaDB, the monstrously fast and scalable database.

Agenda
Introduction

Over this series, you built a working LSM tree: you flush to persist the memtable to disk and compact to reclaim space.
Yet, you’ve been single-threaded so far. This week, we lift that constraint: flush and compaction will run in the background while you keep serving requests.
There are many ways to add concurrency. The approach here is to introduce a versioned, ref-counted catalog that lets readers take a stable snapshot while background flush/compaction proceeds.
A catalog holds references to:
The current memtable.
The current WAL.
The current MANIFEST.
Each request pins one catalog version for the duration of the operation.
When a flush or compaction completes, the system creates a new catalog version. Old resources (e.g., obsolete SSTables) are not deleted immediately. Instead, each catalog tracks a refcount of in-flight requests. Once an old catalog’s refcount drops to zero and a newer catalog exists, you can safely garbage-collect the resources that appear in the old version but not in the new one.
For example, with two catalog versions (red = older version’s elements, blue = newer element”):
 are shaded red to mark older elements, while in Catalog v2 the MANIFEST and SSTable 4 are shaded blue to indicate newer ones.")
Once we can guarantee that catalog v1 is no longer referenced, we can delete the old MANIFEST, SST-2 and SST-3.
Another example: a flush produced a new memtable and WAL file:

In this case, once vatalog v1 has no remaining references, we can free the old memtable and delete the old WAL file.
Your Tasks
💬 If you want to share your progress, discuss solutions, or collaborate with other coders, join the community Discord server (#kv-store-engine channel):
Catalog
Add a
Catalogdata structure that tracks:Memtable reference.
WAL path.
MANIFEST path.
Version (monotonic).
Refcount of active readers.
Implement a
Catalogmanager that keeps catalog versions in memory:Acquire() → Catalog:Pick the latest catalog.
Increment its refcount.
Return it.
Release(Catalog):Decrement the refcount of the catalog.
If refcount is zero and there’s a new catalog version:
Remove the current catalog.
Remove elements present in the current catalog but not in the latest version (files, WAL, etc.)
NewCatalog(memtable, walPath, manifestPath):Create a new catalog based on the provided data.
Assign a unique, monotonic version.
At startup:
Read from the authoritative MANIFEST (latest MANIFEST file).
Treat any files not listed in MANIFEST as orphans and delete them.
Read all WAL files you still have on disk, in order, to rebuild the in-memory state.
Create the current catalog version from the reconstructed state.
Start the background worker.
Background Workers
In a nutshell, flush and compaction will move to the background. You’ll use internal queues plus worker pools to ensure no overlapping work on the same resources: at most one flush running at a time, and at most one compaction running at a time.
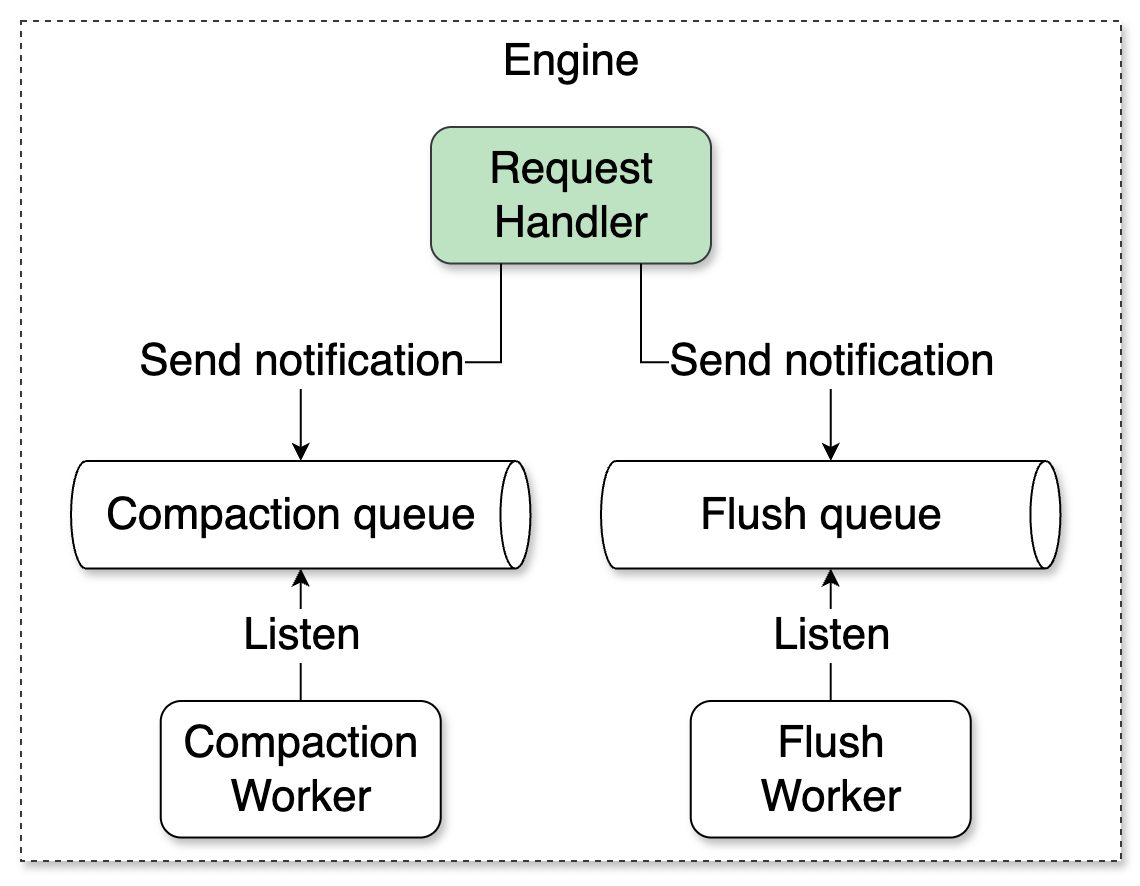
Compaction:
Keep the same trigger: Every 10,000 update requests.
Behavior:
Do not run compaction in the request path.
On compaction trigger: Post a notification to an internal queue and return.
Worker:
A single background thread listens on the queue and runs the actual work.
Similar compaction process, except:
Do not overwrite the existing WAL file. Instead, create a new
WAL-<version+1>file.Create a new catalog that references the new WAL.
Flush:
Keep the same trigger: When the memtable contains 2,000 entries.
Behavior:
Do not run flush in the request path.
On flush trigger:
Allocate a new memtable and create a new WAL file for subsequent writes.
Post a notification to an internal queue.
Return immediately to the caller.
Worker:
A single background thread listens on the queue and runs the actual work.
Similar flush process, except:
Do not overwrite the existing MANIFEST file. Instead, create a new
MANIFEST-<version+1>file.Create a new catalog referencing the new MANIFEST.
GET/PUT/DELETE
Acquire a catalog from the manager.
Do the operation using paths/refs from that catalog.
Release the catalog.
Client & Validation
Concurrent requests make deterministic assertions harder. For example, suppose the validation file contains the following requests that can run in parallel:
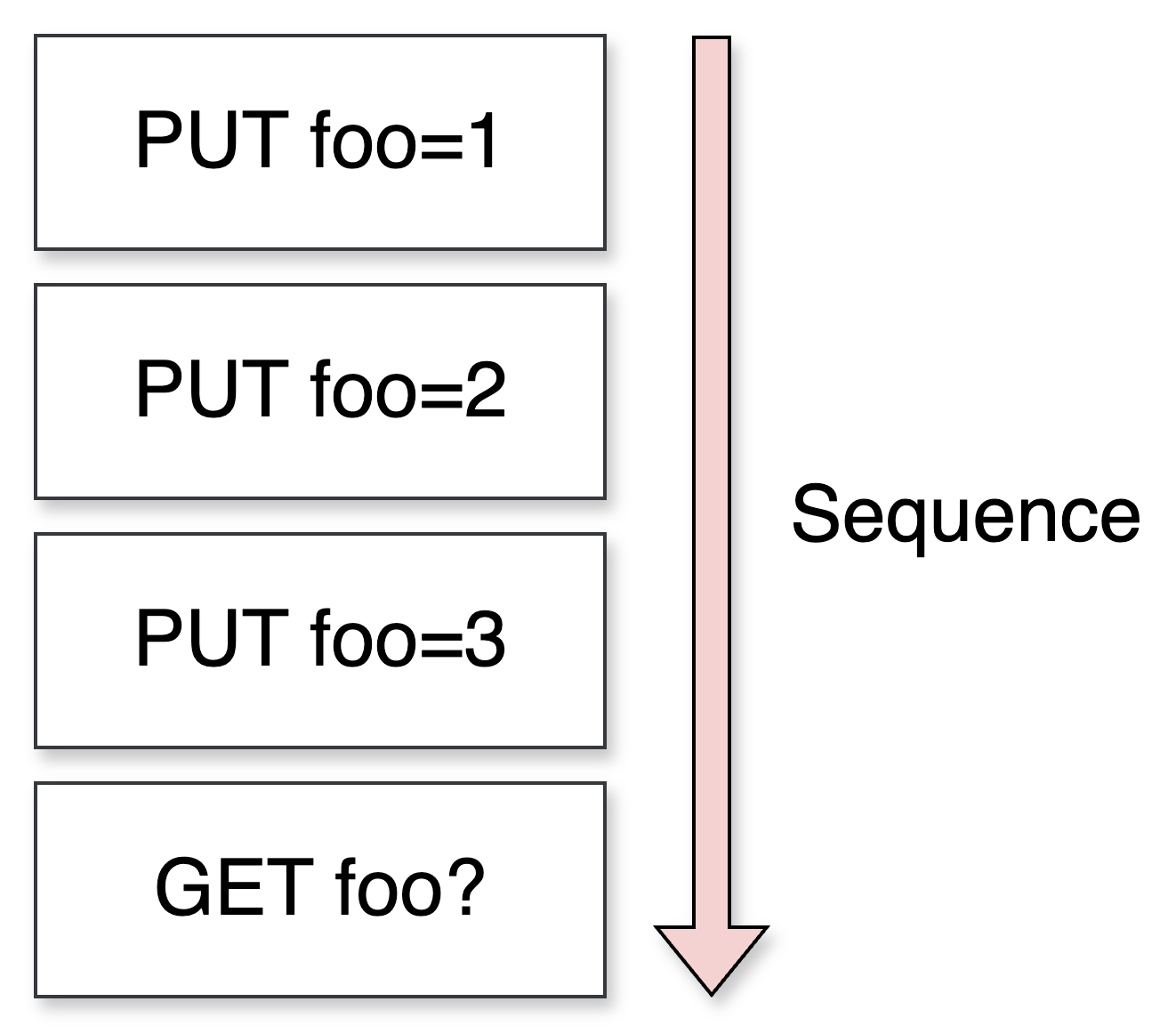
What should you assert for GET foo: 1, 2, or 3?
To make validation deterministic, you will handle barriers: all requests before a barrier must finish before starting the next block. You will also relax GET checks: a GET is valid if it returns any value written for a key before the last barrier.
A similar example with barriers:
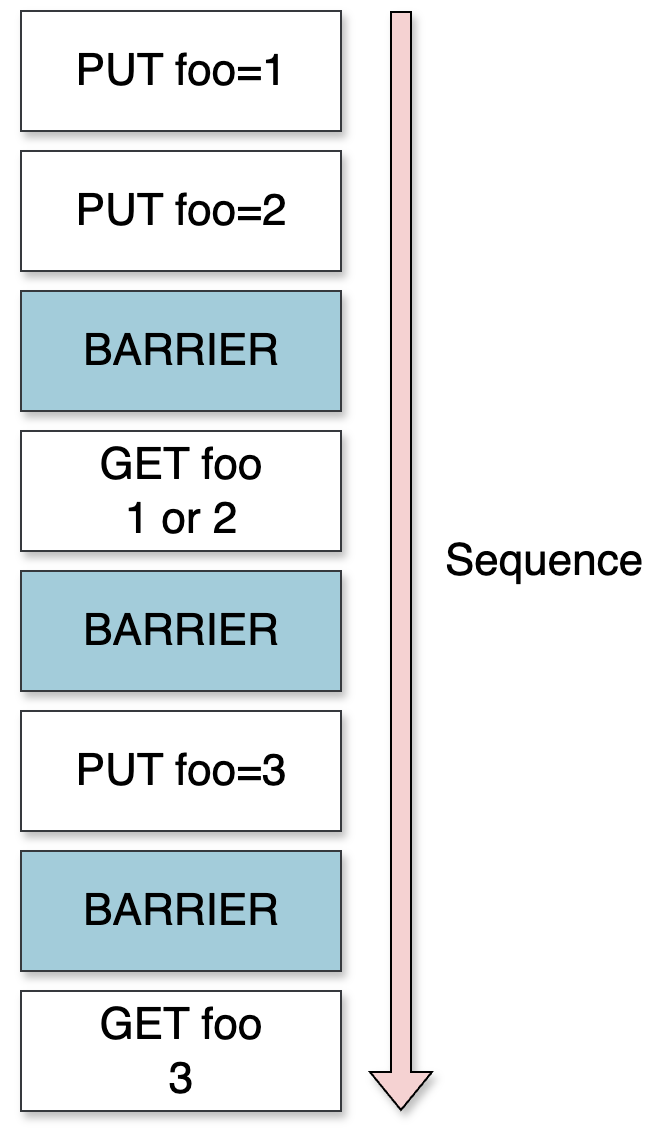
The first two
PUTrequests run in parallel.The first barrier waits for both to complete.
The first GET should accept either
1or2.The second
GETrequest should accept only3.
File Format
The new validation file is a sequence of blocks separated by BARRIER instructions:
(PUT|DELETE) <key> <value>
(PUT|DELETE) <key> <value>
...
BARRIER # New instruction
GET <key> [<value1> <value2> ... <valueK>]
GET <key> [<value1> <value2> ... <valueK>]
...
BARRIERAll the lines between two barriers form a block.
On
BARRIERinstruction, wait for all in-flight requests in the current block to finish before starting the next block.PUT/DELETElines are issued in parallel within their block.GETlines are also issued in parallel within their block.GET <key> [<value1> <value2> ... <valueKmeans the response must be any one of the list values.
Download and run your client against a new file: concurrency.txt.
[Optional] Flush Anticipation
When the memtable reaches 80% of capacity:
Pre-allocate the next memtable in memory.
Pre-create/rotate to the next WAL on disk.
Wrap Up
That's it for the whole series.
You implemented a fully functional LSM tree:
Started with a memtable (hashtable) and a flush that writes immutable SSTables to disk.
Added a WAL for durability.
Handled deletes and compaction to reclaim space.
Introduced leveling and key-range partitioning to speed up reads.
Switched to block-based SSTables with indexing.
Added Bloom filters and replaced the memtable with a radix trie for faster lookups.
Finally, introduced concurrency: a simple, single-threaded foreground path with flush and compaction running in the background.
I hope you had fun building it. Thank you for following the series, and special thanks to our partner, ScyllaDB!
Further Notes
To get more information on how things work in production databases, you can read how RocksDB keeps track of live SST files. The Catalog structure is inspired by RocksDB’s VersionSet.
Conflict resolution is one aspect we’re missing in the series (maybe as a follow-up?) A versioned catalog is enough for reads, but what about conflicting writes?
Suppose two clients, Alice and Bob, update the same key around the same time. A simple policy to resolve conflicts is latest wins. The database can serialize operations for the same key to ensure the latest request wins:
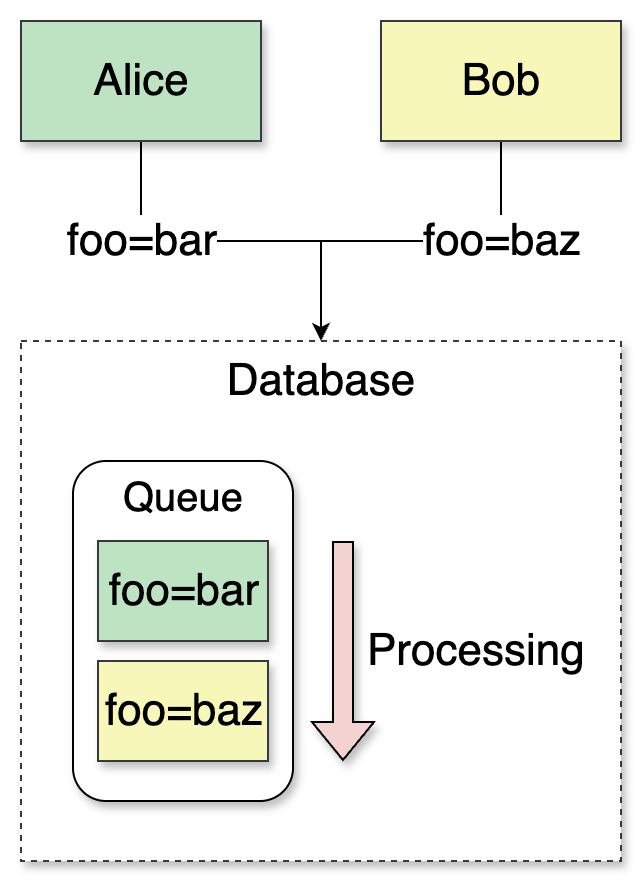
In this example, the database ends up with foo=baz as the latest state.
This approach works with one node. But what about databases composed of multiple nodes? Say the two requests go to two different nodes at roughly the same time:
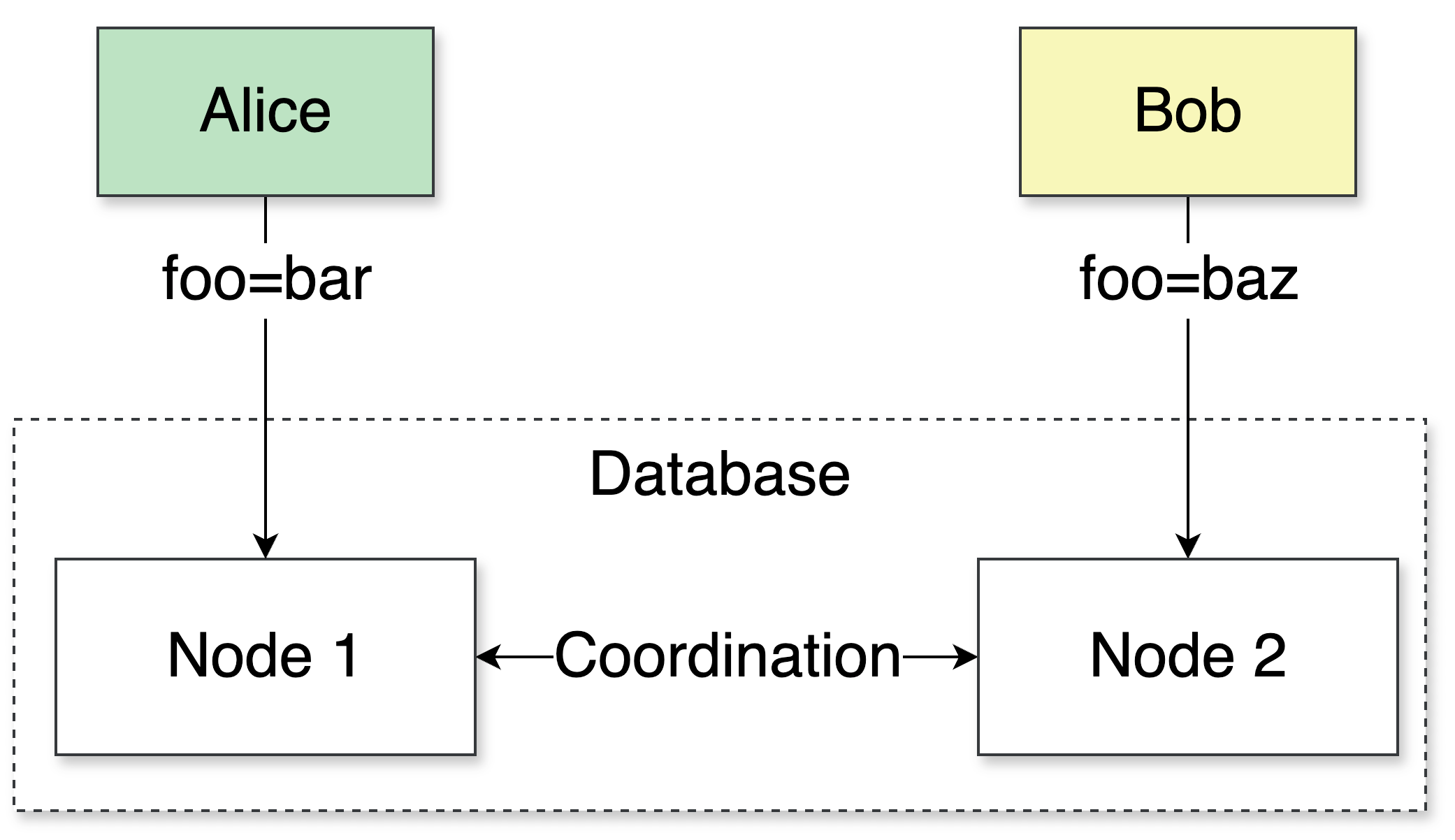
With multiple nodes, the database must resolve conflicts consistently. There are two common ways:
Coordination via a leader (consensus): Route both writes to the same leader node, which solves the conflict and determines the end state.
Reconcile with comparable timestamps: Attach a timestamp to each write and store it with the key. By timestamp, we don’t mean relying on wall-clock time but a logical clock, so that “later“ is well-defined across nodes.
If we go with the second approach and start storing (key, value, timestamp) data, we also unlock something production systems use: consistent snapshots. A read can include a timestamp, and the database returns the last version at or before that time; hence, providing a consistent view of the data, even while flush/compaction runs in the background.
This pattern has a name: Multi-Version Concurrency Control (MVCC). It involves keeping multiple versions per key instead of only the last one, reading using a chosen point in time, and deleting old versions once they are no longer needed.
See how ScyllaDB handles timestamp conflict resolution for more information.

❤️ If you enjoyed this post, please hit the like button.